梯度下降优化
1、归一化 Normalization
1.1、归一化目的
梯度下降的原理和应用,我们已经在前面课程中进行了学习,大家仔细观察下图。
不同方向的陡峭度 是不一样的,即不同维度的数值大小是不同。也就是说梯度下降的快慢是不同的:
如果维度多了,就是超平面 (了解一下霍金所说的宇宙十一维空间),很难画出来了,感受一下下面这张图的空间维度情况。
如果拿多元线性回归举例的话,因为多元线性回归的损失函数 MSE 是凸函数,所以我们可以把损失函数看成是一个碗。然后下面的图就是从碗上方去俯瞰!哪里是损失最小的地方呢?当然对应的就是碗底的地方!所以下图碗中心的地方颜色较浅的区域就是损失函数最小的地方。
上面两张图都是进行梯度下降,你有没有发现,略有不同啊?两张图形都是鸟瞰图,左边的图形做了归一化处理,右边是没有做归一化的俯瞰图。
啥是归一化呢?请带着疑问跟我走~
我们先来说一下为什么没做归一化是右侧图示,举个例子假如我们客户数据信息,有两个维度,一个是用户的年龄,一个是用户的月收入,目标变量是快乐程度。
name
age
salary
happy
路博通
36
7000
100
马老师
42
20000
180
赵老师
22
30000
164
……
……
……
……
我们可以里面写出线性回归公式, y = θ 1 x 1 + θ 2 x 2 + b y = \theta_1x_1 + \theta_2x_2 + b y = θ 1 x 1 + θ 2 x 2 + b
我们把 x 1 x_1 x 1 x 2 x_2 x 2 θ 1 x 1 = θ 2 x 2 \theta_1x_1 = \theta_2x_2 θ 1 x 1 = θ 2 x 2 x 1 ≪ x 2 x_1 \ll x_2 x 1 ≪ x 2 θ 1 ≫ θ 2 \theta_1 \gg \theta_2 θ 1 ≫ θ 2 远大于 )。
这样是不是就比较好理解为什么之前右侧示图里为什么 θ 1 > θ 2 \theta_1 > \theta_2 θ 1 > θ 2 θ \theta θ μ \mu μ σ \sigma σ θ 1 \theta_1 θ 1 θ 2 \theta_2 θ 2 θ 1 \theta_1 θ 1 θ 1 t a r g e t \theta_1^{target} θ 1 t a r g e t θ 2 \theta_2 θ 2 θ 2 t a r g e t \theta_2^{target} θ 2 t a r g e t
因为 x 1 ≪ x 2 x_1 \ll x_2 x 1 ≪ x 2 g j = ( h θ ( x ) − y ) x j g_j= (h_{\theta}(x) - y)x_j g j = ( h θ ( x ) − y ) x j g 1 ≪ g 2 g_1 \ll g_2 g 1 ≪ g 2 θ j n + 1 = θ j n − η ∗ g j \theta_j^{n+1} = \theta_j^n - \eta * g_j θ j n + 1 = θ j n − η ∗ g j θ 1 \theta_1 θ 1 ≪ \ll ≪ 远小于 ) θ 2 \theta_2 θ 2
总结一下 ,根据上面得到的两个结论 ,它俩之间是互相矛盾的 ,意味着最后 θ 2 \theta_2 θ 2 θ 1 \theta_1 θ 1 θ \theta θ θ 2 \theta_2 θ 2 θ 1 \theta_1 θ 1 θ 2 \theta_2 θ 2
结论:
归一化的一个目的是,使得梯度下降在不同维度 θ \theta θ
经过归一化处理,收敛的速度,明显快了!
1.2、归一化本质
做归一化的目的是要实现**“共同富裕”**,而之所以梯度下降优化时不能达到步调一致的根本原因其实还是 x 1 x_1 x 1 x 2 x_2 x 2
答案自然就出来了,就是把 x 1 x_1 x 1 x 2 x_2 x 2 x 1 、 x 2 、 … … 、 x n x_1、x_2、……、x_n x 1 、 x 2 、 …… 、 x n
1.3、最大值最小值归一化
也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 - 1]之间 。转换函数如下:
X ∗ = X − X _ m i n X _ m a x − X _ m i n X^* = \frac{X - X\_min}{X\_max -X\_min} X ∗ = X _ ma x − X _ min X − X _ min
其实我们很容易发现使用最大值最小值归一化(min-max标准化)的时候,优点是一定可以把数值归一到 0 ~ 1 之间,缺点是如果有一个离群值 (比如马云的财富),正如我们举的例子一样,会使得一个数值为 1,其它数值都几乎为 0,所以受离群值的影响比较大!
代码演示:
1 2 3 4 5 6 7 8 9 import numpy as np1 ,10 ,size = 10 )100 ,300 ,size = 10 )print ('归一化之前的数据:' )min (axis = 0 )) / (x.max (axis = 0 ) - x.min (axis = 0 ))print ('归一化之后的数据:' )
使用scikit-learn函数:
1 2 3 4 5 6 7 8 9 10 11 import numpy as npfrom sklearn.preprocessing import MinMaxScaler1 ,10 ,size = 10 )100 ,300 ,size = 10 )print ('归一化之前的数据:' )print ('归一化之后的数据:' )
1.4、0-均值标准化
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化,也叫做Z-score标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,转化函数为:
X ∗ = X − μ σ X^* = \frac{X - \mu}{\sigma} X ∗ = σ X − μ
其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
μ = 1 n ∑ i = 1 n x i \mu = \frac{1}{n}\sum\limits_{i = 1}^nx_i μ = n 1 i = 1 ∑ n x i
σ = 1 n ∑ i = 1 n ( x i − μ ) 2 \sigma = \sqrt{\frac{1}{n}\sum\limits_{i = 1}^n(x_i - \mu)^2} σ = n 1 i = 1 ∑ n ( x i − μ ) 2
相对于最大值最小值归一化来说,因为标准归一化除以了标准差,而标准差的计算会考虑到所有样本数据,所以受到离群值的影响会小一些,这就是除以方差的好处!但是,0-均值标准化不一定会把数据缩放到 0 ~ 1 之间了。既然是0均值,也就意味着,有正有负!
1 2 3 4 5 6 7 8 9 import numpy as np1 ,10 ,size = 10 )100 ,300 ,size = 10 )print ('归一化之前的数据:' )0 )) / x.std(axis = 0 )print ('归一化之后的数据:' )
使用scikit-learn函数:
1 2 3 4 5 6 7 8 9 10 11 import numpy as npfrom sklearn.preprocessing import StandardScaler1 ,10 ,size = 10 )100 ,300 ,size = 10 )print ('归一化之前的数据:' )print ('归一化之后的数据:' )
那为什么要减去均值呢?其实做均值归一化还有一个特殊的好处(对比最大值最小值归一化,全部是正数0~1),我们来看一下梯度下降的式子,你就会发现 α \alpha α y ^ − y = h θ ( x ) − y \hat{y} - y = h_{\theta}(x) - y y ^ − y = h θ ( x ) − y x 1 x_1 x 1 x 2 x_2 x 2 α \alpha α w 1 t + 1 w_1^{t+1} w 1 t + 1 w 2 t + 1 w_2^{t+1} w 2 t + 1 w t w_t w t w ∗ w^* w ∗ w 1 w_1 w 1 w 2 w_2 w 2 w 1 w_1 w 1 w 2 w_2 w 2 w 1 w_1 w 1 w 2 w_2 w 2
那我们如何才能做到让 w 1 w_1 w 1 w 2 w_2 w 2 x 1 x_1 x 1 x 2 x_2 x 2
结论:0-均值标准化 处理数据之后,属性有正有负,可以让梯度下降沿着最优路径进行~
注意:
我们在做特征工程的时候,很多时候如果对训练集的数据进行了预处理,比如这里讲的归一化,那么未来对测试集的时候,和模型上线来新的数据的时候,都要进行相同的 数据预处理流程,而且所使用的均值和方差是来自当时训练集的均值和方差!
因为我们人工智能要干的事情就是从训练集数据中找规律,然后利用找到的规律去预测新产生的数据。这也就是说假设训练集和测试集以及未来新来的数据是属于同分布的!从代码上面来说如何去使用训练集的均值和方差呢?就需要把 scaler 对象持久化, 回头模型上线的时候再加载进来去对新来的数据进行处理。
1 2 3 4 import joblib'scale' ) 'scale' )
2、正则化 Regularization
2.1、过拟合欠拟合
欠拟合(under fit):还没有拟合到位,训练集和测试集的准确率都还没有到达最高,学的还不到位。
过拟合(over fit):拟合过度,训练集的准确率升高的同时,测试集的准确率反而降低。学的过度了(走火入魔),做过的卷子都能再次答对(死记硬背),考试碰到新的没见过的题就考不好(不会举一反三)。
恰到好处(just right):过拟合前,训练集和测试集准确率都达到巅峰。好比,学习并不需要花费很多时间,理解的很好,考试的时候可以很好的把知识举一反三。
正则化就是防止过拟合,增加模型的鲁棒性 ,鲁棒是 Robust 的音译,也就是强壮的意思。就像计算机软件在面临攻击、网络过载等情况下能够不死机不崩溃,这就是软件的鲁棒性。鲁棒性调优就是让模型拥有更好的鲁棒性,也就是让模型的泛化能力和推广 能力更加的强大。
举例子说明:下面两个式子描述同一条直线那个更好?
y = 0.3 x 1 + 0.4 x 2 + 0.5 y = 0.3x_1 + 0.4x_2 + 0.5 y = 0.3 x 1 + 0.4 x 2 + 0.5
y = 3 x 1 + 4 x 2 + 5 y = 3x_1 + 4x_2 + 5 y = 3 x 1 + 4 x 2 + 5
第一个更好,因为下面的公式是上面的十倍,当 w 越小公式的容错的能力就越好。因为把测试数据带入公式中如果测试集原来是 [32, 128] 在带入的时候发生了一些偏差,比如说变成 [30, 120] ,第二个模型结果就会比第一个模型结果的偏差大的多。公式中 y = W T x y = W^Tx y = W T x
所以正则化(鲁棒性调优)的本质就是牺牲模型在训练集上的正确率来提高推广、泛化能力, W 在数值上越小越好,这样能抵抗数值的扰动 。同时为了保证模型的正确率 W 又不能极小。 故而人们将原来的损失函数加上一个惩罚项,这里面损失函数就是原来固有的损失函数,比如回归的话通常是 MSE,分类的话通常是 cross entropy 交叉熵,然后在加上一部分惩罚项来使得计算出来的模型 W 相对小一些来带来泛化能力。
常用的惩罚项有L1 正则项或者 L2 正则项:
L 1 = ∣ ∣ w ∣ ∣ 1 = ∑ i = 1 n ∣ w i ∣ L_1 = ||w||_1 = \sum\limits_{i = 1}^n|w_i| L 1 = ∣∣ w ∣ ∣ 1 = i = 1 ∑ n ∣ w i ∣ L 2 = ∣ ∣ w ∣ ∣ 2 = ∑ i = 1 n ( w i ) 2 L_2 = ||w||_2 = \sqrt{\sum\limits_{i = 1}^n(w_i)^2} L 2 = ∣∣ w ∣ ∣ 2 = i = 1 ∑ n ( w i ) 2
其实 L1 和 L2 正则的公式数学里面的意义就是范数,代表空间中向量到原点的距离:
L p = ∣ ∣ X ∣ ∣ p = ∑ i = 1 n x i p p , X = ( x 1 , x 2 , … … x n ) L_p = ||X||_p = \sqrt[p]{\sum\limits_{i = 1}^nx_i^p} , X = (x_1,x_2,……x_n) L p = ∣∣ X ∣ ∣ p = p i = 1 ∑ n x i p , X = ( x 1 , x 2 , …… x n )
当我们把多元线性回归损失函数加上 L2 正则的时候,就诞生了 Ridge 岭回归。当我们把多元线性回归损失函数加上 L1 正则的时候,就孕育出来了 Lasso 回归。其实 L1 和 L2 正则项惩罚项可以加到任何算法的损失函数上面去提高计算出来模型的泛化能力的。
2.2、套索回归(Lasso)
先从线性回归开始,其损失函数如下:
J ( θ ) = 1 2 ∑ i = 1 n ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta) = \frac{1}{2}\sum\limits_{i = 1}^n(h_{\theta}(x^{(i)}) - y^{(i)})^2 J ( θ ) = 2 1 i = 1 ∑ n ( h θ ( x ( i ) ) − y ( i ) ) 2
L1正则化的损失函数,令J 0 = J ( θ ) J_0 = J(\theta) J 0 = J ( θ )
J = J 0 + α ∗ ∑ i = 1 n ∣ w i ∣ J = J_0 + \alpha * \sum\limits_{i = 1}^n|w_i| J = J 0 + α ∗ i = 1 ∑ n ∣ w i ∣
令 L 1 = α ∗ ∑ i = 1 n ∣ w i ∣ L_1 = \alpha * \sum\limits_{i = 1}^n|w_i| L 1 = α ∗ i = 1 ∑ n ∣ w i ∣
J = J 0 + L 1 J = J_0 + L_1 J = J 0 + L 1
其中 J 0 J_0 J 0 α \alpha α J J J J J J J 0 J_0 J 0 J 0 J_0 J 0 L 1 = α ∗ ∑ i = 1 n ∣ w i ∣ L_1 = \alpha * \sum\limits_{i = 1}^n|w_i| L 1 = α ∗ i = 1 ∑ n ∣ w i ∣ J = J 0 + L 1 J = J_0 + L_1 J = J 0 + L 1 L 1 L_1 L 1 J 0 J_0 J 0 考虑二维的情况 ,即只有两个权值 w 1 、 w 2 w_1、w_2 w 1 、 w 2 L 1 = ∣ w 1 ∣ + ∣ w 2 ∣ L_1 = |w_1| + |w_2| L 1 = ∣ w 1 ∣ + ∣ w 2 ∣ J 0 J_0 J 0 L 1 L_1 L 1 w 1 、 w 2 w_1、w_2 w 1 、 w 2
图中等值线是J 0 J_0 J 0 L 1 L_1 L 1 L 1 = ∣ w 1 ∣ + ∣ w 2 ∣ L_1 = |w_1| + |w_2| L 1 = ∣ w 1 ∣ + ∣ w 2 ∣
在图中,当 J 0 J_0 J 0 L 1 L_1 L 1 J 0 J_0 J 0 L 1 L_1 L 1 L 1 L_1 L 1 ( w 1 , w 2 ) = ( 0 , w ) (w_1,w_2) = (0,w) ( w 1 , w 2 ) = ( 0 , w ) L 1 L_1 L 1 J 0 J_0 J 0 L 1 L_1 L 1
而正则化前面的系数 α \alpha α L 1 L_1 L 1 α \alpha α L 1 L_1 L 1 α \alpha α L 1 L_1 L 1 ( w 1 , w 2 ) = ( 0 , w ) (w_1,w_2) = (0,w) ( w 1 , w 2 ) = ( 0 , w )
代码演示 α \alpha α
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import matplotlib.pyplot as pltlambda x : 1 - x0 ,1 ,100 )'equal' )'green' )lambda x : 1 /3 - x 0 ,1 /3 ,100 )'red' )2 ,2 )2 ,2 )'right' ].set_color('None' ) 'top' ].set_color('None' ) 'bottom' ].set_position(('data' , 0 )) 'left' ].set_position(('data' , 0 ))'./图片/13-alpha对方框影响.png' ,dpi = 200 )
权重更新规则如下:
损失函数:
J ( θ ) = 1 2 ∑ i = 1 n ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta) = \frac{1}{2}\sum\limits_{i = 1}^n(h_{\theta}(x^{(i)}) - y^{(i)})^2 J ( θ ) = 2 1 i = 1 ∑ n ( h θ ( x ( i ) ) − y ( i ) ) 2
L 1 = α ∗ ∑ i = 1 n ∣ w i ∣ L_1 = \alpha * \sum\limits_{i = 1}^n|w_i| L 1 = α ∗ i = 1 ∑ n ∣ w i ∣
J = J 0 + L 1 J = J_0 + L_1 J = J 0 + L 1
更新规则:
θ j n + 1 = θ j n − η ∗ ∂ ∂ θ j J \theta_j^{n + 1} = \theta_j^{n} - \eta * \frac{\partial}{\partial \theta_j}J θ j n + 1 = θ j n − η ∗ ∂ θ j ∂ J
θ j n + 1 = θ j n − η ∗ ∂ ∂ θ j ( J 0 + L 1 ) \theta_j^{n + 1} = \theta_j^{n} - \eta * \frac{\partial}{\partial \theta_j}(J_0 + L_1) θ j n + 1 = θ j n − η ∗ ∂ θ j ∂ ( J 0 + L 1 )
∂ ∂ θ j J 0 = ∑ i = 1 n ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \frac{\partial}{\partial \theta_j}J_0 =\sum\limits_{i = 1}^{n} (h_{\theta}(x^{(i)}) - y^{(i)} )x_j^{(i)} ∂ θ j ∂ J 0 = i = 1 ∑ n ( h θ ( x ( i ) ) − y ( i ) ) x j ( i )
∂ ∂ θ j L 1 = α ∗ s g n ( w i ) \frac{\partial}{\partial \theta_j}L_1 = \alpha * sgn(w_i) ∂ θ j ∂ L 1 = α ∗ s g n ( w i )
其中 J 0 J_0 J 0 L 1 L_1 L 1 s g n ( w i ) sgn(w_i) s g n ( w i )
s g n ( w i ) = { 1 , w i > 0 − 1 , w i < 0 sgn(w_i) = \begin{cases}1, &w_i > 0\\-1,&w_i < 0\end{cases} s g n ( w i ) = { 1 , − 1 , w i > 0 w i < 0
注意当 w i = 0 w_i = 0 w i = 0
综上所述 ,L1正则化权重更新如下:
θ j n + 1 = θ j n − η ∑ i = 1 n ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) − η ∗ α ∗ s g n ( w i ) \theta_j^{n + 1} = \theta_j^{n} -\eta\sum\limits_{i = 1}^{n} (h_{\theta}(x^{(i)}) - y^{(i)} )x_j^{(i)} - \eta*\alpha * sgn(w_i) θ j n + 1 = θ j n − η i = 1 ∑ n ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) − η ∗ α ∗ s g n ( w i )
Lasso回归和线性回归相比,多了一项:− η ∗ α ∗ s g n ( w i ) -\eta * \alpha * sgn(w_i) − η ∗ α ∗ s g n ( w i )
$\eta $ 大于零,表示梯度下降学习率
α \alpha α 当w i w_i w i s g n ( w i ) = 1 sgn(w_i) = 1 s g n ( w i ) = 1 η ∗ α \eta * \alpha η ∗ α w i w_i w i
当w i w_i w i s g n ( w i ) = − 1 sgn(w_i) = -1 s g n ( w i ) = − 1 η ∗ α \eta * \alpha η ∗ α w i w_i w i
有的书本上公式会这样写,其中 λ \lambda λ
θ j n + 1 = θ j n − η ∑ i = 1 n ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) − η ∗ λ ∗ s g n ( w i ) \theta_j^{n + 1} = \theta_j^{n} -\eta\sum\limits_{i = 1}^{n} (h_{\theta}(x^{(i)}) - y^{(i)} )x_j^{(i)} - \eta*\lambda * sgn(w_i) θ j n + 1 = θ j n − η i = 1 ∑ n ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) − η ∗ λ ∗ s g n ( w i )
2.3、岭回归(Ridge)
也是先从线性回归开始,其损失函数如下:
J ( θ ) = 1 2 ∑ i = 1 n ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta) = \frac{1}{2}\sum\limits_{i = 1}^n(h_{\theta}(x^{(i)}) - y^{(i)})^2 J ( θ ) = 2 1 i = 1 ∑ n ( h θ ( x ( i ) ) − y ( i ) ) 2
L2正则化的损失函数(对L2范数,进行了平方运算),令J 0 = J ( θ ) J_0 = J(\theta) J 0 = J ( θ )
J = J 0 + α ∗ ∑ i = 1 n ( w i ) 2 J = J_0 + \alpha * \sum\limits_{i = 1}^n(w_i)^2 J = J 0 + α ∗ i = 1 ∑ n ( w i ) 2
令 L 2 = α ∗ ∑ i = 1 n ( w i ) 2 L_2 = \alpha * \sum\limits_{i = 1}^n(w_i)^2 L 2 = α ∗ i = 1 ∑ n ( w i ) 2
J = J 0 + L 2 J = J_0 + L_2 J = J 0 + L 2
同样可以画出他们在二维平面上的图形,如下:
二维平面下 L2 正则化的函数图形是个圆(绝对值的平方和,是个圆),与方形相比,被磨去了棱角。因此 J 0 J_0 J 0 L 2 L_2 L 2 w 1 、 w 2 w_1、w_2 w 1 、 w 2
权重更新规则如下:
损失函数:
J ( θ ) = 1 2 ∑ i = 1 n ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta) = \frac{1}{2}\sum\limits_{i = 1}^n(h_{\theta}(x^{(i)}) - y^{(i)})^2 J ( θ ) = 2 1 i = 1 ∑ n ( h θ ( x ( i ) ) − y ( i ) ) 2
L 2 = α ∗ ∑ i = 1 n ( w i ) 2 L_2 = \alpha * \sum\limits_{i = 1}^n(w_i)^2 L 2 = α ∗ i = 1 ∑ n ( w i ) 2
J = J 0 + L 2 J = J_0 + L_2 J = J 0 + L 2
更新规则:
θ j n + 1 = θ j n − η ∗ ∂ ∂ θ j J \theta_j^{n + 1} = \theta_j^{n} - \eta * \frac{\partial}{\partial \theta_j}J θ j n + 1 = θ j n − η ∗ ∂ θ j ∂ J
θ j n + 1 = θ j n − η ∗ ∂ ∂ θ j ( J 0 + L 2 ) \theta_j^{n + 1} = \theta_j^{n} - \eta * \frac{\partial}{\partial \theta_j}(J_0 + L_2) θ j n + 1 = θ j n − η ∗ ∂ θ j ∂ ( J 0 + L 2 )
$\frac{\partial}{\partial \theta_j}J_0 =\sum\limits_{i = 1}^{n} (h_{\theta}(x^{(i)}) - y^{(i)} )x_j^{(i)} $
∂ ∂ θ j L 2 = 2 α w i \frac{\partial}{\partial \theta_j}L_2 = 2\alpha w_i ∂ θ j ∂ L 2 = 2 α w i
其中 J 0 J_0 J 0 L 2 L_2 L 2
综上所述 ,L2正则化权重更新如下(2 α 2\alpha 2 α α \alpha α
θ j n + 1 = θ j n ( 1 − η ∗ α ) − η ∗ ∑ i = 1 n ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \theta_j^{n + 1} = \theta_j^{n}(1-\eta * \alpha) -\eta *\sum\limits_{i = 1}^{n} (h_{\theta}(x^{(i)}) - y^{(i)} )x_j^{(i)} θ j n + 1 = θ j n ( 1 − η ∗ α ) − η ∗ i = 1 ∑ n ( h θ ( x ( i ) ) − y ( i ) ) x j ( i )
其中 α \alpha α η \eta η θ j \theta_j θ j ( 1 − η ∗ α ) (1-\eta * \alpha) ( 1 − η ∗ α ) θ j \theta_j θ j θ \theta θ
有的书本上,公式写法可能不同 :其中 λ \lambda λ
θ j n + 1 = θ j n ( 1 − η ∗ λ ) − η ∗ ∑ i = 1 n ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \theta_j^{n + 1} = \theta_j^{n}(1-\eta * \lambda) -\eta *\sum\limits_{i = 1}^{n} (h_{\theta}(x^{(i)}) - y^{(i)} )x_j^{(i)} θ j n + 1 = θ j n ( 1 − η ∗ λ ) − η ∗ i = 1 ∑ n ( h θ ( x ( i ) ) − y ( i ) ) x j ( i )
3、线性回归衍生算法
接下来,我们一起学习一下scikit-learn中为我们提供的线性回归衍生算法,根据上面所学的原理,对比线性回归加深理解。
3.1、Ridge算法使用
这是scikit-learn官网给出的岭回归的,损失函数公式,注意,它用的矩阵表示,里面用到范数运算。
min w ∣ ∣ X w − y ∣ ∣ 2 2 + α ∣ ∣ w ∣ ∣ 2 2 \underset{w}\min || X w - y||_2^2 + \alpha ||w||_2^2 w min ∣∣ Xw − y ∣ ∣ 2 2 + α ∣∣ w ∣ ∣ 2 2
L2正则化和普通线性回归系数对比:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import numpy as npfrom sklearn.linear_model import Ridgefrom sklearn.linear_model import SGDRegressor2 *np.random.rand(100 , 5 )1 ,10 ,size = (5 ,1 ))1 ,10 ,size = 1 )100 , 1 )print ('原始方程的斜率:' ,w.ravel())print ('原始方程的截距:' ,b)1 , solver='sag' )print ('岭回归求解的斜率:' ,ridge.coef_)print ('岭回归求解的截距:' ,ridge.intercept_)'l2' ,alpha=0 ,l1_ratio=0 )1 ,))print ('随机梯度下降求解的斜率是:' ,sgd.coef_)print ('随机梯度下降求解的截距是:' ,sgd.intercept_)
结论:
和没有正则项约束线性回归对比,可知L2正则化,将方程系数进行了缩小
α \alpha α Ridge回归源码解析:
alpha:正则项系数
fit_intercept:是否计算 w 0 w_0 w 0
normalize:是否做归一化
max_iter:最大迭代次数
tol:结果的精确度
solver:优化算法的选择
3.2、Lasso算法使用
这是scikit-learn官网给出的套索回归的,损失函数公式,注意,它用的矩阵表示,里面用到范数运算。
min w 1 2 n samples ∣ ∣ X w − y ∣ ∣ 2 2 + α ∣ ∣ w ∣ ∣ 1 \underset{w}\min { \frac{1}{2n_{\text{samples}}} ||X w - y||_2 ^ 2 + \alpha ||w||_1} w min 2 n samples 1 ∣∣ Xw − y ∣ ∣ 2 2 + α ∣∣ w ∣ ∣ 1
公式中多了一项:1 2 n s a m p l e s \frac{1}{2n_{samples}} 2 n s am pl es 1
L1正则化和普通线性回归系数对比:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import numpy as npfrom sklearn.linear_model import Lassofrom sklearn.linear_model import SGDRegressor2 *np.random.rand(100 , 20 )20 ,1 )1 ,10 ,size = 1 )100 , 1 )print ('原始方程的斜率:' ,w.ravel())print ('原始方程的截距:' ,b)0.5 )print ('套索回归求解的斜率:' ,lasso.coef_)print ('套索回归求解的截距:' ,lasso.intercept_)'l2' ,alpha=0 , l1_ratio=0 )1 ,))print ('随机梯度下降求解的斜率是:' ,sgd.coef_)print ('随机梯度下降求解的截距是:' ,sgd.intercept_)
结论:
和没有正则项约束线性回归对比,可知L1正则化,将方程系数进行了缩减,部分系数为0,产生稀疏模型
α \alpha α Lasso回归源码解析:
alpha:正则项系数
fit_intercept:是否计算 w 0 w_0 w 0
normalize:是否做归一化
precompute:bool 类型,默认值为False,决定是否提前计算Gram矩阵来加速计算
max_iter:最大迭代次数
tol:结果的精确度
warm_start:bool类型,默认值为False。如果为True,那么使⽤用前⼀次训练结果继续训练。否则从头开始训练
3.3、Elastic-Net算法使用
这是scikit-learn官网给出的弹性网络回归的,损失函数公式,注意,它用的矩阵表示,里面用到范数运算。
min w 1 2 n samples ∣ ∣ X w − y ∣ ∣ 2 2 + α ρ ∣ ∣ w ∣ ∣ 1 + α ( 1 − ρ ) 2 ∣ ∣ w ∣ ∣ 2 2 \underset{w}\min { \frac{1}{2n_{\text{samples}}} ||X w - y||_2 ^ 2 + \alpha \rho ||w||_1 +
\frac{\alpha(1-\rho)}{2} ||w||_2 ^ 2} w min 2 n samples 1 ∣∣ Xw − y ∣ ∣ 2 2 + α ρ ∣∣ w ∣ ∣ 1 + 2 α ( 1 − ρ ) ∣∣ w ∣ ∣ 2 2
Elastic-Net 回归,即岭回归和Lasso技术的混合。弹性网络是一种使用 L1, L2 范数作为先验正则项训练的线性回归模型。 这种组合允许学习到一个只有少量参数是非零稀疏的模型,就像 Lasso 一样,但是它仍然保持一些像 Ridge 的正则性质。我们可利用 l1_ratio 参数控制 L1 和 L2 的凸组合。
弹性网络在很多特征互相联系(相关性,比如身高 和体重 就很有关系)的情况下是非常有用的。Lasso 很可能只随机考虑这些特征中的一个,而弹性网络更倾向于选择两个。
在实践中,Lasso 和 Ridge 之间权衡的一个优势是它允许在迭代过程中继承 Ridge 的稳定性。
弹性网络回归和普通线性回归系数对比:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import numpy as npfrom sklearn.linear_model import ElasticNetfrom sklearn.linear_model import SGDRegressor2 *np.random.rand(100 , 20 )20 ,1 )1 ,10 ,size = 1 )100 , 1 )print ('原始方程的斜率:' ,w.ravel())print ('原始方程的截距:' ,b)1 , l1_ratio = 0.7 )print ('弹性网络回归求解的斜率:' ,model.coef_)print ('弹性网络回归求解的截距:' ,model.intercept_)'l2' ,alpha=0 , l1_ratio=0 )1 ,))print ('随机梯度下降求解的斜率是:' ,sgd.coef_)print ('随机梯度下降求解的截距是:' ,sgd.intercept_)
结论:
和没有正则项约束线性回归对比,可知Elastic-Net网络模型,融合了L1正则化L2正则化
Elastic-Net 回归源码解析:
alpha:混合惩罚项的常数
l1_ratio:弹性网混合参数,0 <= l1_ratio <= 1,对于 l1_ratio = 0,惩罚项是L2正则惩罚。对于 l1_ratio = 1是L1正则惩罚。对于 0
fit_intercept:是否计算 w 0 w_0 w 0
normalize:是否做归一化
precompute:bool 类型,默认值为False,决定是否提前计算Gram矩阵来加速计算
max_iter:最大迭代次数
tol:结果的精确度
warm_start:bool类型,默认值为False。如果为True,那么使⽤用前⼀次训练结果继续训练。否则从头开始训练
4、多项式回归
4.1、多项式回归基本概念
升维的目的是为了去解决欠拟合的问题的,也就是为了提高模型的准确率为目的的,因为当维度不够时,说白了就是对于预测结果考虑的因素少的话,肯定不能准确的计算出模型。
在做升维的时候,最常见的手段就是将已知维度进行相乘(或者自乘)来构建新的维度,如下图所示。普通线性方程,无法拟合规律,必须是多项式,才可以完美拟合曲线规律,图中是二次多项式。
对于多项式回归来说主要是为了扩展线性回归算法来适应更广泛的数据集,比如我们数据集有两个维度 x 1 、 x 2 x_1、x_2 x 1 、 x 2 y ^ = w 0 + w 1 x 1 + w 2 x 2 \hat{y} = w_0 + w_1x_1 + w_2x_2 y ^ = w 0 + w 1 x 1 + w 2 x 2 x 1 、 x 2 x_1、x_2 x 1 、 x 2 x 1 、 x 2 、 x 1 2 、 x 2 2 、 x 1 x 2 x_1、x_2、x_1^2、x_2^2、x_1x_2 x 1 、 x 2 、 x 1 2 、 x 2 2 、 x 1 x 2 y ^ = w 0 + w 1 x 1 + w 2 x 2 + w 3 x 1 2 + w 4 x 2 2 + w 5 x 1 x 2 \hat{y} = w_0 + w_1x_1 + w_2x_2 + w_3x_1^2 + w_4x_2^2 + w_5x_1x_2 y ^ = w 0 + w 1 x 1 + w 2 x 2 + w 3 x 1 2 + w 4 x 2 2 + w 5 x 1 x 2
此时拟合出来的方程就是曲线,可以解决一些线性回归的欠拟合问题!
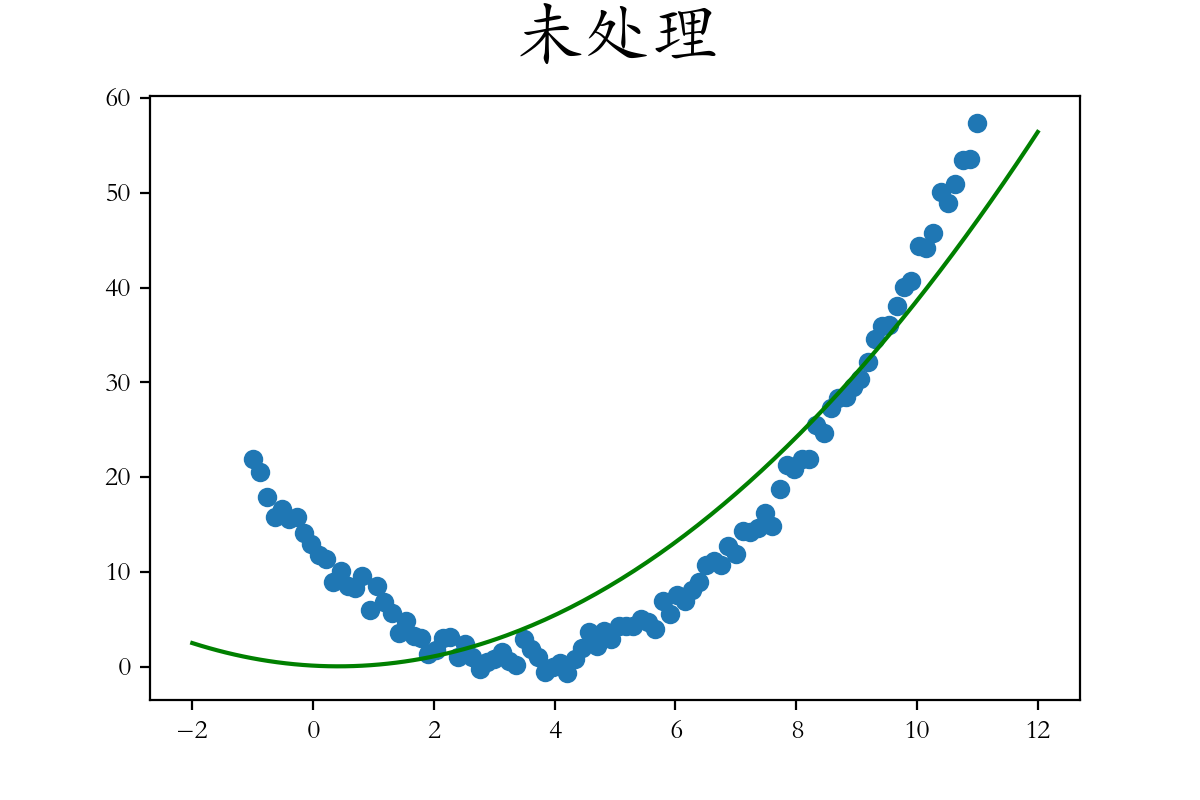
4.2、多项式回归实战1.0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import numpy as npimport matplotlib.pyplot as pltfrom sklearn.linear_model import LinearRegression1 ,11 ,num = 100 )5 )**2 + 3 *X -12 + np.random.randn(100 )1 ,1 )2 ,12 ,num = 200 ).reshape(-1 ,1 )'red' )2 ],axis = 1 )2 ],axis = 1 )0 ],y_test_2,color = 'green' )
结论:
不进行多项式升维,拟合出来的曲线,是线性的直线,和目标曲线无法匹配
使用np.concatenate()进行简单的,幂次合并,注意数据合并的方向axis = 1
数据可视化时,注意切片,因为数据升维后,多了平方这一维
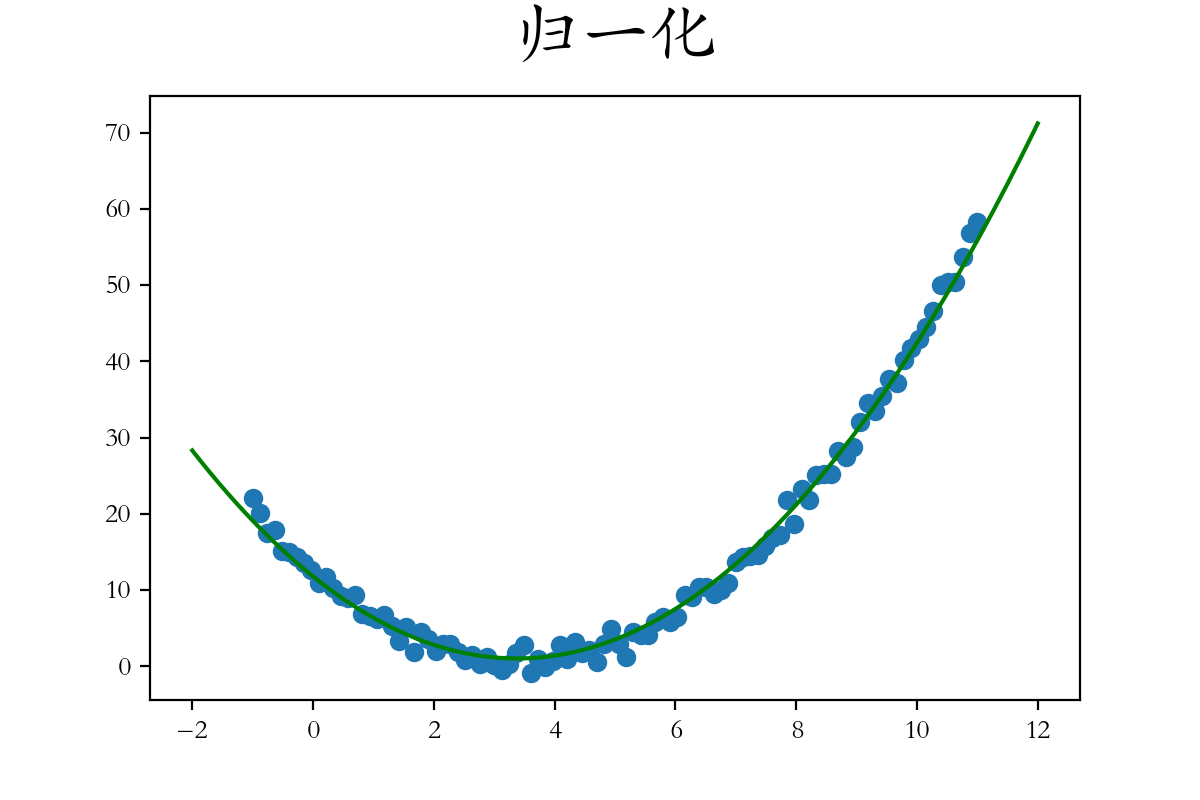
4.3、多项式回归实战2.0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import numpy as npimport matplotlib.pyplot as pltfrom sklearn.preprocessing import PolynomialFeatures,StandardScalerfrom sklearn.linear_model import SGDRegressor1 ,11 ,num = 100 )5 )**2 + 3 *X -12 + np.random.randn(100 )1 ,1 )2 ,12 ,num = 200 ).reshape(-1 ,1 )'l2' ,eta0 = 0.01 )1 ],y_test,color = 'green' )
结论:
eta0表示学习率,设置合适的学习率,才能拟合成功
多项式升维,需要对数据进行Z-score归一化处理,效果更佳出色
SGD随机梯度下降需要调整参数,以使模型适应数据
5、代码实战天猫双十一销量预测
天猫双十一,从2009年开始举办,第一届成交额仅仅0.5亿,后面呈现了爆发式的增长,那么这些增长是否有规律呢?是怎么样的规律,该如何分析呢?我们使用多项式回归一探究竟!
数据可视化,历年天猫双十一销量数据:
1 2 3 4 5 6 7 8 9 10 11 12 import numpy as npfrom sklearn.linear_model import SGDRegressorimport matplotlib.pyplot as plt'font.size' ] = 18 9 ,6 ))2009 ,2020 )0.5 ,9.36 ,52 ,191 ,350 ,571 ,912 ,1207 ,1682 ,2135 ,2684 ])0.5 ,color = 'green' )'red' )
有图可知,在一定时间内,随着经济的发展,天猫双十一销量与年份的关系是多项式关系!假定,销量和年份之间关系是三次幂关系:
f ( x ) = w 1 x + w 2 x 2 + w 3 x 3 + b f(x) = w_1x + w_2x^2 + w_3x^3 + b f ( x ) = w 1 x + w 2 x 2 + w 3 x 3 + b
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import numpy as npfrom sklearn.linear_model import SGDRegressorimport matplotlib.pyplot as pltfrom sklearn.preprocessing import PolynomialFeaturesfrom sklearn.preprocessing import StandardScaler12 ,9 ))2009 ,2020 )0.5 ,9.36 ,52 ,191 ,350 ,571 ,912 ,1207 ,1682 ,2135 ,2684 ])1 ,1 )3 )'l2' ,eta0 = 0.5 ,max_iter = 5000 )5 ,6 ,100 ).reshape(-1 ,1 )1 ],y_test,color = 'green' )1 ],y)6 ,y_test[-1 ],color = 'red' )0 ,4096 )6 ,y_test[-1 ] + 100 ,round (y_test[-1 ],1 ),ha = 'center' )5 ,7 ),np.arange(2009 ,2021 ))
结论:
数据预处理,均值移除。如果特征基准值和分散度 不同在某些算法(例如回归算法,KNN等)上可能会大大影响了模型的预测能力。通过均值移除,大大增强数据的离散化 程度。
多项式升维,需要对数据进行Z-score归一化处理,效果更佳出色
SGD随机梯度下降需要调整参数,以使模型适应多项式数据
从2020年开始,天猫双十一统计的成交额改变了规则为11.1日~11.11日的成交数据(之前的数据为双十一当天的数据),2020年成交额为4980 亿元
可以,经济发展有其客观规律,前11年高速发展(曲线基本可以反应销售规律),到2020年是一个转折点
6、代码实战中国人寿保费预测
6.1、数据加载与介绍
1 2 3 4 5 import numpy as npimport pandas as pd'./中国人寿.xlsx' )print (data.shape)
数据介绍:
共计1338条保险数据,每条数据7个属性
最后一列charges是保费
前面6列是特征,分别为:年龄、性别、体重指数、小孩数量、是否抽烟、所在地区
6.2、EDA数据探索
1 2 3 4 5 6 7 8 9 10 11 12 import seaborn as sns'charges' ],shade = True ,hue = data['sex' ])'charges' ],shade = True ,hue = data['region' ])'charges' ],shade = True ,hue = data['smoker' ])'charges' ],shade = True ,hue = data['children' ],palette='Set1' )
总结:
不同性别对保费影响不大,不同性别的保费的概率分布曲线基本重合,因此这个特征无足轻重,可以删除
地区同理
吸烟与否对保费的概率分布曲线差别很大,整体来说不吸烟更加健康,那么保费就低,这个特征很重要
家庭孩子数量对保费有一定影响
6.3、特征工程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 data = data.drop(['region' , 'sex' ], axis=1 )def convert (df,bmi ):'bmi' ] = 'fat' if df['bmi' ] >= bmi else 'standard' return df1 , args=(30 ,))'charges' , axis=1 ) 'charges' ]
6.4、特征升维
1 2 3 4 5 6 7 8 9 10 11 12 13 from sklearn.linear_model import LinearRegressionfrom sklearn.linear_model import ElasticNetfrom sklearn.metrics import mean_squared_error,mean_squared_log_errorfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import PolynomialFeatures0.2 )2 , include_bias = False )
6.5、模型训练与评估
普通线性回归:
1 2 3 4 5 6 7 8 9 model_1 = LinearRegression()print ('测试数据得分:' ,model_1.score(X_train_poly,y_train))print ('预测数据得分:' ,model_1.score(X_test_poly,y_test))print ('训练数据均方误差:' ,np.sqrt(mean_squared_error(y_train,model_1.predict(X_train_poly))))print ('测试数据均方误差:' ,np.sqrt(mean_squared_error(y_test,model_1.predict(X_test_poly))))print ('训练数据对数误差:' ,np.sqrt(mean_squared_log_error(y_train,model_1.predict(X_train_poly))))print ('测试数据对数误差:' ,np.sqrt(mean_squared_log_error(y_test,model_1.predict(X_test_poly))))
弹性网络回归:
1 2 3 4 5 6 7 8 9 10 model_2 = ElasticNet(alpha = 0.3 ,l1_ratio = 0.5 ,max_iter = 50000 )print ('测试数据得分:' ,model_2.score(X_train_poly,y_train))print ('预测数据得分:' ,model_2.score(X_test_poly,y_test))print ('训练数据均方误差为:' ,np.sqrt(mean_squared_error(y_train,model_2.predict(X_train_poly))))print ('测试数据均方误差为:' ,np.sqrt(mean_squared_error(y_test,model_2.predict(X_test_poly))))print ('训练数据对数误差为:' ,np.sqrt(mean_squared_log_error(y_train,model_2.predict(X_train_poly))))print ('测试数据对数误差为:' ,np.sqrt(mean_squared_log_error(y_test,model_2.predict(X_test_poly))))
结论:
进行EDA数据探索,可以查看无关紧要特征
进行特征工程:删除无用特征、特征离散化、特征提取。这对机器学习都至关重要
对于简单的数据(特征比较少)进行线性回归,一般需要进行特征升维
选择不同的算法,进行训练和评估,从中筛选优秀算法